
Contents
Background
Our project goal is to:
Build a recommendation engine that recommends new songs to add to a given playlist purely based on musical features obtained from Spotify.
The operational definition is to:
Build a model that makes a decision of inclusion or exclusion for any given new song S_new in any given playlist P that contains existing songs
Note that this project is unlike a traditional recommender model where we have to predict affinity through ratings or consumption (e.g. movies for netflix, items for amazon). We do not have a ground truth from Spotify on this so we do not use a traditional collaborative filtering framework. This brings us to the considerations we need to make.
There are a few considerations we need to take into account in our models, which are addressed at different points of our analysis:
-
Similarity: Similarity of songs within playlists is a sound assumption to make for recommending new songs for a given playlist
-
Novelty: The value of song recommendations is that there is an element of novelty/exploration, so users like to see new songs that are familiar but offer just enough novelty to keep them interested. We will try to build this in structurally through our system.
-
Drift: We want to build in bounds within our model to address song drift. This is the idea that if an algorithm recommends songs that move the music features away from the original average music features of a given playlist over time, we encounter drift. The user will then have to re-seed the playlist with their original tracks to get the algorithm back on track. We want to avoid this by imposing some bounds on our model. For example, in our baseline model, our bounds were the cluster boundaries.
-
Representativeness: Is a song representative of the playlist and/or is a playlist representative of certain songs? Not all playlists are made equally in terms of diversity. We devise models that account for differences in diversity of playlists’ musical features.
-
Ease of deployment: An engineering team should be able to deploy the recommender system easily. Simpler models are valued here. Models that take less time to run since latency is of the essence in a world where music is released rapidly everyday.
Breaking this problem down, there are actually two steps:
-
Identification: This is identifying whether a song should be included or excluded from a playlist. This step is where traditional ML/ data science technqiues can help the most. We’ve done a lot of work in this realm with our models, because this is the most testable with hard metrics like accuracy and F1.
-
Deployment: The candidate set of playlists that may come out of identification will most likely be quite large, given the nature of our dataset. How do we actually deploy a recommendation? In our monte carlo method, we use randomness to figure out priority of playlists to add to first. Depending on how rapidly Spotify’s playlist team wants to show new songs to a user, the team can dial up or dial down the number of playlists to recommend a song using a priority list. The efficacy of our methods for this part of the problem is not as readily observable since we don’t have user satisfaction info here. However, we used our a priori considerations above to guide us in the right direction.
See our Literature Review for more details.
Data Engineering
We encountered multiple issues with our dataset. For one, the “playlist-song” dataset comprised of just under 70 million rows total. A dataset like this was far too large to manage locally on our machines without being confined to importing selected CSVs as a subsample, which would be significantly limiting down the road.
Thus, we decided to host our data on Google Cloud Platform (GCP) via their distributed big data store, BigQuery. This would allow us to efficiently query and manipulate any subset of the million playlist dataset using their SQL-like interface. After some research, we were able to configure our setups such that we could retrieve the data through BigQuery and store it in our Juptyer notebooks to perform the EDAs locally. Ultimately, this setup allowed us to analyze larger datasets; instead of confining ourselves to one CSV of ~70,000 rows, we were able to conduct analysis performantly on data sets of up to 500,000 and theoretically more, though we decided that this was a decent cutoff point.
Additionally, moving our data over into GCP proved invaluable during the initial steps of querying each song through the Spotify features API. Since songs are duplicated across playlists, using BigQuery, we were able to extract a uniquified dataset of just 2 million songs from the 70 million rows and save them to a separate table. With this technique, a scraping endeavor that would’ve taken an estimated 19+ hours total was reduced to under an hour. From there, it was a matter of performing a simple outer join query on the original songs dataset to associate the features back to each playlist-song row. Lastly, this ability to isolate and query uniquified songs enabled us to sample a truly random subset of the song data (without including duplicate songs or introducing bias by selecting songs clustered around a set of playlists in a given CSV) for our EDA.
Further challenges arose when we discovered that the playlist IDs were unique only to each file, as opposed to being a globally unique playlist ID (each file included playlists with a PID of 0 - 999). This would become an issue for any analyses we wanted to run on playlist-specific data. To account for this, we re-processed each CSV, adding an additional column called “unique_pid” which combined the file number with the playlist ID, and re-processed the data in BQ.
EDA
In this section, we’ll briefly recap our EDA from milestone 3. We began by examining the correlations of the audio features in our data set. The correlogram below depicts correlations that are intuitive. For example, acousticness is strongly negatively correlated with loudness and energy. On the other hand, energy is positively correlated with loudness and valence (the musical “positiveness” associated with a track). In conclusion, although there is some multi-collinearity between the features, we can still include them all, given that their absolute correlations are under 0.75

The next step in our analysis was to find similarities between the songs in our dataset. To do so, we applied k-means clustering to our data. K-means is an unsupervised learning method that groups data into clusters according to the mean value of their features. At a high level, it works by initializing a user-specified number of k centroids, then assigns each data point to the closest centroid Towards Data Science: K-Means
We identified 12 salient clusters to group our data into. As you can see in the plots below, some features (speechiness, key) are quite helpful in differentiating our songs, while some are virtually useless (tempo).













Baseline Modeling
In our first iteration, we used a combination of supervised and unsupervised learning to generate the initial recommendation approach:
- Labeling (K-means): cluster universe of all songs in all playlists into 12 clusters based on spotify music features. This serves as a 1-dimensional label with 12 categories which makes computation extremely efficient if we run supervised learning over it.
- Classification (K-Nearest Neighbors): Upon receiving a new song that is
not labeled with one of the 12 categories, we can use K-nearest neighbors based
on musical features to identify the cluster in which this new song falls. We
found that the model with
K=100gave us the highest cross-validation scores (mean=97.8%) and are confident in its ability to correctly put the new song in an appropriate cluster.
Labeling (K-means) Results
As an example, the below shows the cluster assignment generated by our model for the following three songs:
- Mozart: Piano Concerto No.21 in C Major
- Kendrick Lamar: alright
- Slayer: Raining Blood
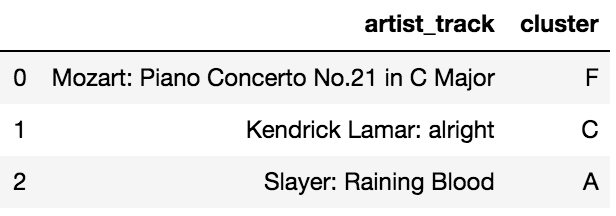
Let’s compare the cluster assignments for Slayer’s Raining Blood, and Mozart’s Piano Concerto No.21 in C Major. Clearly, these are two songs that couldn’t be more different. Slayer is a 1980’s thrash metal band known for its aggression, “fast, percussive beats, low-register guitar riffs, and shredding-style lead guitar work”. Mozart on the other hand is, well, Mozart.
First, examining Mozart’s cluster (F) in the plots above, we can see that this is the cluster associated with the lowest levels of loudness, energy, tempo, and speechiness, and the highest levels of acousticness and instrumentalness of all our clusters. In short, this Mozart Piano Concerto has been assigned to a quiet, slow, calm, and soothing cluster with low levels of vocals.
The cluster for Slayer’s Raining Blood (A), on the other hand, is associated with the highest levels of loudness, energy, liveness, and tempo in all our clusters. In addition, cluster A has some of the lowest levels of acousticness and instrumentalness. It also has the second highest level of speechiness. In summary, Raining Blood’s cluster is one associated with loud, fast-paced, highly energetic music featuring a high level of vocals.
Thus, the qualitative analysis of our cluster assignments validates the groupings that k-means created for us.
Classification (K-Nearest Neighbors)
In addition, we can also use our model to make song recommendations. Below, you can see the top 10 “closest” songs for each of the following three songs above:



As we can see, the top recommendations for Mozart’s Piano Concerto are pieces by composers such as Schubert, Dvorak, Einaudi, and Holst. It also features several instrumental tracks from movie soundtracks. For Kendrick Lamar’s punchy hip-hop anthem, alright, we have recommended songs by other hip-hop artists such as Lil Jon, Lexxmatiq, and the Notorious B.I.G. Finally, our recommendations for Slayer’s Raining Blood feature songs by similar thrash and death metal bands such as Necrophagist, Amon Amarth, Carnifex, and Judas Priest.
Interestingly, for both Raining Blood and alright, the top recommended song is the song itself. This is due to the fact that these songs are present in different albums by the same artist. As you can see the “distance” for these duplicate songs from the target song is zero, which makes sense.
Model Refinement
Writing the prequel: unique playlist models using KNN without clustering
After creating the KNN model that learns song cluster labels, we then asked the question, “What is the simplest model we can make to serve as a comparison?”. Like a good YA novelist, we decided to write a prequel to our baseline model.
This model was the same as the baseline model in the sense that it utilized KNN to do supervised learning.
However, this model differed from the baseline model in a few ways:
- Targets and features: Our targets and features changed here.
- Targets: Instead of predicting the cluster in which the song belongs (and thus, getting us a candidate set of playlists within that cluster), we now predicted the decision of inclusion and exclusion directly into a playlist (binary: 1 for inclusion and 0 for exclusion).
- Features: Our features required no pre-processing and are the pure Spotify musical features obtained from the API.
-
Individual models per playlist: While the baseline model was an omnibus model that looked at all songs across playlists, this framework makes a separate model for each playlist. This addresses the question of representativeness and diversity mentioned in the background. Some playlists might be more diverse than others and/or more representative of certain musical features. We wanted to capture this variety in our models. We ran a random sample of 250 playlists and all of their songs. There were about 17,500 songs in total.
-
Accuracy metric: Instead of evaluating whether a song accurately fell into a cluster, we now evaluated whether a song accurately fell into specific playlists. Playlists were on average about 70 songs big.
-
Downsampling playlist non-examples: To get balanced data sets for each model run, we had to downsample non-examples in the dataset. This was not relatively an issue when we were dealing with clusters since the number of examples there were quite large.
- Stratified validation splits: Because of the large number of playlists in the data and the sparsity of examples for each, the model required stratified validation splits, which again, was not as much of an issue for the cluster model.
While this approach captures the heterogeneity of playlists (one of our considerations), our findings show that this approach falls prey to overfitting. From a product perspective (as opposed to a mathematical perspective), it did not address our initial considerations as well as the baseline model.
The plots below tell us a few things:
-
Overfitting occured. There was a huge gap between train and test accuracy and F1 scores. F1 scores are more revealing because they represent the harmonic mean between precision and recall which are both good measures for unbalanced and sparse data sets like ours. This is not great for generalizing to new songs.
-
Our intuition that playlists are heterogenous is founded. The models that arose from each had very different accuracies.
-
Novelty is overrated. The results of these models gives a clue into how much novelty is in these playlists. K=2 performed the best here, meaning the act of averaging relatively close data points gave better predictions than taking into account further data points.
Figure: distribution of 250 playlist models, given different levels of k




Conclusion: This was not a great approach to predicting recommendations, because
- This tended to overfit. Did not give great predictions for new songs.
- Violated our ease of deployment consideration. For 250 playlists, the models took ~6 minutes to train and predict. Spotify has over thousands of playlists. Deploying this quickly would be a considerable computational feat. Also, with KNN since it is not a structural model, the time sink lies in the prediction step as opposed to the fitting step. Predicting many new songs with this approach becomes costly very quickly. Our baseline cluster learning model, took negligible time to predict!
- This had no constraints to curb drift. Our baseline had clusters as boundaries to protect us from drift. This was not true in this appraoch. Since we were taking nearest neighbors, the assumption is that multiple neighbors will “cancel” each other out in terms of musical features. However, this can very much be untrue, in which case, over time, playlists can experience drift.
- Novelty was overrated The one inference we can make from the performance of these models is that songs close to each other tend to predict inclusion and exclusion in playlists well.
Better recommendations: inverse distance weighted monte carlo
Next, we turned to the playlist assignment problem. Specifically, the question we sought to answer was: given the audio features of a particular song, which playlist should it be added to? To generate better playlist assignments, we turned to iterations of a couple different Monte Carlo-based methods. To do so, we leveraged the our earlier clustering work. In particular, when a new song’s cluster had been predicted, we could then say that this song was eligible to be added to an existing song’s playlist within that cluster, given that all songs within the cluster were similar to one another.
To determine which playlist would receive the new song, we implemented the following high-level logic:
- Randomly sample one song out of all existing songs in the cluster
- For the selected existing song, randomly select a playlist associated with that song (a song can have multiple playlists associated with it)
- Add the new song to the playlist sampled in step 2
For the random sampling step, we tried two different approaches:
- True Random Sampling: We selected a single song/playlist using a truly random implementation
- Weighted Sampling: We refined the sampling step in the true random sampling model by weighting in-cluster songs based on distance of music features. Existing songs closer to the new song were weighted more in the sampling procedure based on inverse distance weighting
Example: Lady Gaga’s Bad Romance
To make our Monte Carlo approach more clear, we’ve provided an example of
playlist selection, using Lady Gaga’s Bad Romance. First we used Monte Carlo
simulation with n=10000 iterations to randomly assign our song to a playlist
belonging to a song within Bad Romance’s cluster (identified earlier with
k-means clustering). After doing so, we selected the most commonly assigned
playlist. The most commonly assigned playlist in our simulations was 614690:

Next, we utilized weighted sampling to improve the musical “closeness” of
the assigned playlist to Bad Romance’s. Specifically, for each playlist
available from the songs in Bad Romance’s cluster, we computed the mean
distance of its audio features from it to Bad Romance. We then used the
inverse weight of that distance to sample in the Monte Carlo simulation. In
simpler terms, the closer a playlist was to Bad Romance in terms of audio
features, the higher the probability it would be selected. Again, we ran a
simulation with n=10000 iterations. The most commonly assigned playlist this
time was 3814.

Now, let’s compare the audio features across our naive playlist, our weighted playlist, and Bad Romance itself:



The differences here are subtle because all three are quite close in terms of
audio features. This is a testament to the efficacy of our clustering work
earlier. However, direct your attention to the following audio features: key,
speechiness, acousticness, instrumentalness, liveness. As you can see,
Bad Romance has very low values for each of these fields (close to 0 for
key, acousticness, and instrumentalness). Our weighted Monte Carlo playlist
is much closer to Bad Romance for these fields than that of the naive
playlist.
A reliable workhorse: unique playlist models using regularized logistic regression
So far we our baseline model has assumed that our existing songs are representative of their respective playlists. But what if there are some playlists that are significantly more diverse in musical features than others (i.e. a John Mayer playlist has homogenous “acousticness” levels while a top 40 playlist will feature varying levels of this predictor across songs)?
This calls for us to create playlist-specific models whereby for each song, we can predict the likelihood of playlist inclusion based on in-playlist and out-of-playlist song musical features. Since each model will be specific to a playlist, the diversity/homogeneity/representativeness of features will be fit better than in an omnibus model. Additionally, such structural models offer a worthwhile benefit in that they are more deployment-friendly; inclusion of new songs into a given playlist only requires re-training the playlist in question, whereas omnibus models necessitate an update to the entire system. Thus, we felt that this method––despite its shortcomings, which we will delineate further below––was a worthwhile avenue to explore.
Variable Selection
Since the prediction is categorical (i.e. whether or not a given song belongs in a given playlist) each model will use simple logistic regressions. As above, we use song audio features as our regressors, and while we our earlier EDA indicated some level of multi-collinearity, we’ll elect to include them all into our model given the acceptability of their absolute correlation levels.
Additionally, given the variability of the measurements from one predictor to the next (while most range from 0 to 1, others such as “duration” can comprise of significantly larger values reaching into the thousands), we normalize each predictor prior to training.
Model Selection and Results
Given the time constraints, we did not endeavor to train a model for all playlists; for our explorations, we sampled a dataset of ~30,000 songs across ~500 playlists.
We then looped through each playlist, training each model with L1 regularization to penalize noisy predictors. To create a balanced dataset, we randomly downsampled the number of songs outside of the playlist to ensure we obtained n non-examples, where n is equivalent to the number of songs that were in the playlist.
We plotted our accuracy scores to visualize the effectiveness of our training set:




Overall, the middle 50% of test accuracy scores for our models resided between 0.6 - 0.8. Most of our models, then, do predict with significance, but this pales in comparison to our winning model.
Note that we plotted F1 as well since it represents a harmonic mean of precision and accuracy - which is a better measure of how well our models perform given the sparse nature of our examples. The model overfits due to huge gaps between train and test scores.
Given the structural nature of these models, through our playlist-centric analysis, we were also able to extract insight around our predictors our sample of 500 playlists by calculating the T-values for each of the predictors. Below are the means across each model:
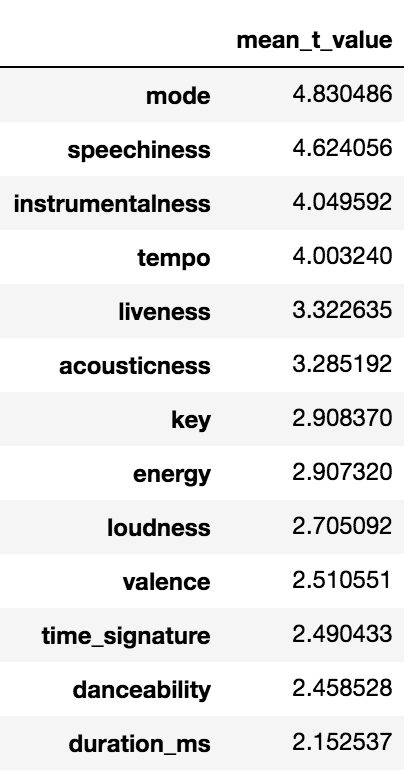
We notice that on average for our playlists, the top three predictors with the highest T-scores are mode (major/minor key), speechiness, and instrumentalness. There are marked differences in mode between sad and happy songs. Speechiness most likely comes from a differentation between more urban genres and others. Instrumental differences are prevalent between classical and pop genres.



On the low end are duration and time_signature, which make sense given that we would not expect a user to like a song any less due to these characteristics.
Conclusion
Our recommendation to the Spotify playlist team is that they employ the following procedure procedure:
-
Identifcation: Create a model that learns to classify songs into clusters and use that to identify playlist candidates for new songs
-
This entails creating labels through a clustering algorithm such as k-means. We found the ideal k turned out to be 12. This allowed for sufficient heterogeneity in the song space. This also makes computation extremely efficient.
-
The cluster labels serve as supervised learning labels whereby song features can be used to predict the cluster in which it belongs. We used the KNN algorithm to do this. Accuracy of identifying the cluster correctly was extremely high (97%) and allowed us to identify candidate playlists associated with in-cluster songs adjacent to the new song.
-
Benefits: This approach is easy to understand and easy to deploy. It addresses the consideration of drift by putting a boundary around eligible playlists (only those that are in-cluster are eligible). It is also accurate in identifying the correct cluster label.
- Deployment:
Use a monte carlo simulation (10000 simulations) to create a priority list of
playlists for which to add the new song
- In each simulation, sample one song from all songs in the predicted cluster of the new song taken from step 1
- Novelty is overrated (see section on KNN for individual playlists). Use inverse distance weighting in the step above. Calculate the distance between the new song and all in-cluster songs using the musical features. Then in the sampling step, weight the closer songs more than songs further out.
- From that one song, sample one playlist associated with that.
- Repeat many times to build a frequency table of playlist appearances. The playlists that appear the most get first dibs on the new song.
Benefits: The simulation allows us to sample from multiple universes to really find what is most representative of the playlist space in the cluster. The inverse distance weighting allows us to exploit our knowledge that novelty is overrated. Songs within playlists tend to stick closely to their average musical features, so weighting in-cluster songs that are nearer to the new song in terms of the musical feature vector during the simulation is an appropriate step to take.
There are two approaches we do not recommend due to overfitting and inability to model sparse examples well.
- Creating individual KNN models for each playlist, using songs’ musical features as predictors
- Creating individual logistic models for each playlist, using songs’ musical features as predictors
While the intuition to capture heterogeneity across playlists was founded, the generalizability to test data was lacking. Ease of deployment was also lacking.
We did however uncover great inference from these failed approaches:
- Novelty is overrated. In the KNN model, k=2 performed the best in terms of predicting inclusion in a playlist. This suggests that songs in playlists are clustered quite tightly together in terms of musical features.
- Structural models allow us to see the most important features. Mode (major/minor), tempo, speechiness, instrumentalness were the most important features in all of the logistic models.
Because of the sparseness of examples for individual playlists, future work would address this augmentation of our dataset with possible user satisfaction metrics (song adds, song listens, etc.). This could also be a dynamic process whereby our recommender engine could add songs and then get immediate feedback through user actions - creating a reinforcement learning system akin to near-miss learning. The problem can be seen through the lens of a teacher (user) - learner (algorithm) relationship.
That being said, we have identified a procedure that works relatively well. Although it does not employ cutting edge ML methods, a little amount of intelligence in the right place and the right time goes a long way.
Appendixes
Finally, we’ve included several appendixes that detail the nuts and bolts of our data engineering, infrastructure, and scraping efforts.